
5

Tags:
databaser

Skrevet af
Bruger #2730
@ 23.05.2003
Velkommen til anden del af føljetonen omkring oprettelse af kuber på Microsofts SQL Server 2000 og Analysis Services der er en komponent til SQL Serveren. Formålet med denne artikel er at bygge videre på den foregående artikel og afsløre hvordan man kommer fra en dejligt modelleret relationel database til en kube indeholdende de data vi har lavet tidligere.
At lave en ny forbindelse til SQL ServerenDen første manøvre der skal gennemgås når man skal oprette en ny kube er at lave en forbindelse mellem den multidimensionelle kube database og det relationelle miljø. Det vi er interesseret i med denne manøvre er at gøre kube databasen i stand til at indlæse alle de data der findes i den relationelle database og bygge en multidimensionel struktur oven på disse data. Det første der skal gøres er at oprette en ny kube database. Det kan gøres ved at højreklikke på din server og vælge "New Database" og herefter give den et navn og vælge ok. Efterfølgende "klappes" databasen ud og der fremkommer nu en håndfuld mapper med forskellige titler. Den vi i første omgang vil bekymre os om er den øverste der hedder "Data Sources". Der højre klikkes igen og vælges "New datasource".
Nu er det bare at vælge den rigtige provider og opsætte en connection, herefter kan der klikkes "Test Connection" for at test om der er forbindelse til den relationelle database. Det skal i den forbindelse lige siges et par ord om forbindelsen. Hvis man tilføjer nye tabeller eller kolonner i den relationelle del af løsningen vil disse ikke være synlige for kuben før forbindelsen bliver refreshed. Dette kan gøres ved at højreklikke på forbindelsen og vælge "Refresh".
 Kubetyper
KubetyperDer er to forskellige kube typer der kan laves, hver med deres særpræg. Den første er den almindelig kube. En kube indeholder typisk et enkelt forretningsområde, fx. salg, personale eller lager. Disse kuber indeholder en eller flere dimensioner, delte eller lokale. Samt en eller flere measures (beregninger). Beregninger er altid knyttet til en enkelt kube, da det eksempelvis ikke vil give mening at se lagerhastighed på en medarbejder! Dette er også typisk en af grundene til at man deler det op i forskellige forretningsområder, for ikke at vildlede brugeren. Den anden type kube der kan laves er en virtuel kube. I princippet er det en overbygning på flere kuber således det er muligt at analysere på tværs af forretningsområder. Det kunne for eksempel være at se sygefravær for Salgsafdelingen sammenlignet med sygefravær for Marketing. Kuber laves ved at åbne folderen "Cubes" og vælge "New cube" for herefter at vælge om man vil guides af en wizard eller om man bare vil gøre det med en editor.
 De forskellige dimensioner
De forskellige dimensionerDer er også to typer dimensioner, lokale dimensioner samt delte dimensioner. Lokale dimensioner er dimensioner der kun findes inden for den enkelte kube. Det vil sige at dimensionen ikke kan tilgås udefra af andre kuber (lidt som at have private variabler i de fleste programmeringssprog). Disse lokale dimensioner kan ikke bruges i virtuelle kuber, da de ikke vil være synlige for den virtuelle kube. De delte dimensioner findes på tværs af alle kuber. Det vil sige at enhver kube der har et datagrundlag der understøtter dimensionen kan bruge den hvis den ønsker. De delte dimensioner laves ved at højreklikke på folderen "Shared dimensions" og vælge "new dimension". Igen får man muligheden for at blive guidet af en wizard, eller lave det hele selv. Alle delte dimensioner er tilgængelige i virtuelle kuber.
 At bygge en shared dimension
At bygge en shared dimensionVi vil nu bygge en delt dimension på baggrund af de data vi så i del 1 af denne artikelserie, det er typen vi vil bygge den dimension ud af. Vi starter med at højreklikke på "Shared dimensions" og vælge "New dimension". Vi vælger at lave det med en editor, da det som regel er nemmest. Det første vi gør når editoren åbner er at vælge hvilken fil der skal danne grundlaget for denne dimension. Da vi i del 1 af denne føljeton byggede en dimensionstabel er det meget nærliggende at vælge den som grundlag for vores dimension (vi ved jo også at den er konsistent). Vi får nu en dialogboks der viser vores dimensionsstruktur i venstre side samt tabellen det stammer fra højre side. I bunden er der to tabs, en der hedder "Schema" og en der hedder "Data". Vi står for nuværende på "Schema" - her har vi mulighed for at se vores dimensionsstruktur (man kan godt have flere dimensionstabeller der kan linkes sammen). Når vi skifter over på "Data" ser vi hvordan værdierne i vores dimension er ordnet (den er tom nu da der intet er lavet endnu). Næste skridt er at markere den del af tabellen i højre side vi ønsker at bruge som tekst i vores dimension. Eksempelvis har jeg valgt tekst, herefter højreklikker jeg og vælger "Insert as level". Nu flyttes tekst over i venstre side under "<NEW>" teksten. Når vi vælger at skifte fra tabben "Schema" til tabben "Data", kan vi se at der nu er data i vores dimension.
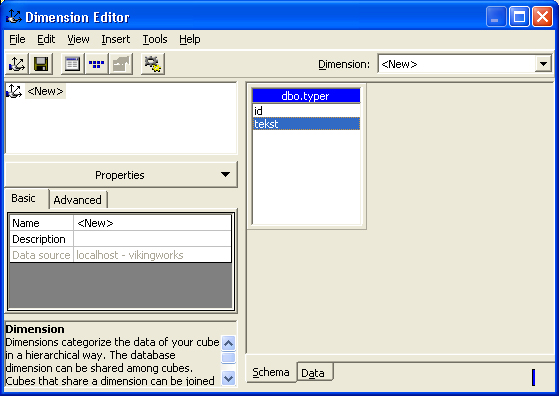
Dimensionen skal nu gemmes og processeres (gemme er diskette ikonet, og processer er ikonet der ligner to tandhjul). Ved at processere henter man al data over fra den relationelle model og bygger en multidimensionen datastruktur i Analysis Services. Det vil samtidig sige at tilføjes der nyt data til din relationelle model skal dimensionerne processeres for at indeholde de nye data. Når man processerer kan man vælge mellem "Rebuild dimension structure" og "Incremental update". I første omgang skal man altid vælge "Rebuild dimension structure" indtil man bliver mere fortrolig med Analysis Services. Når det er sket (man kan godt få fejl ved processeringen, men det er typisk fordi man ikke har konsistens i sine data) kan man lukke processing dialogen og fortsætte med at bygge yderligere dimensioner eller nye kuber.
At bygge en simpel kubeAt bygge en kube foregår meget på samme måde som ved at lave en dimension. Man højreklikker på folderen "Cubes" og vælger "New Cube". Da jeg er mest til editorer, viser jeg hvordan man gør ved brugen af den. De første par manøvrer er nøjagtig som da vi byggede en dimension (sådan da). Man bliver stadig promptet om at vælge en tabel, men denne gang er det en fact tabel vi skal have fat i, og ikke som tidligere en dimensionstabel. Vi vælger nu vores fact tabel (bogsalg) og vi ser næsten det samme billede som da vi byggede dimensionen.
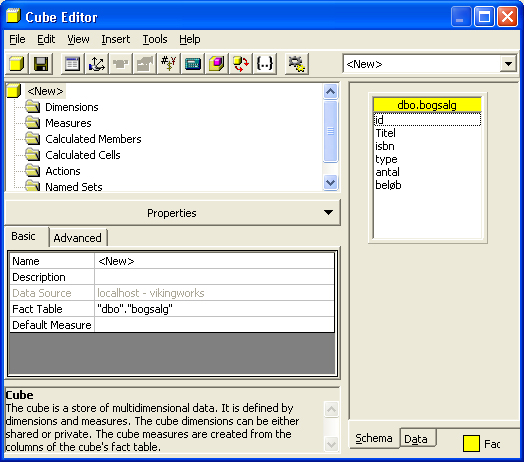
Denne gang er der nogle flere mapper i venstre side til at holde alle de dimensioner og measures vi tilføjer. Det første vi vil gøre et at højreklikke på dimensions mappen i venstre side og vælg at tilføje en dimension (Existing dimension, da vi jo har lavet den på forhånd - lige som i tv køkkenet). Vi får nu mulighed for at vælge mellem alle de shared dimensioner der findes, desværre for os fik vi aldrig lavet mere end en, så den må vi nøjes med. Den vælger vi og klikker "OK". Den nye dimension kommer nu til syne nedenunder mappen dimensions i venstre side. Lidt mere kryptisk er højre side kommet til at se ud, vi har nu fået tilføjet et ny tabel og programmet har automatisk linket dimensionen op mod fact tabellen.
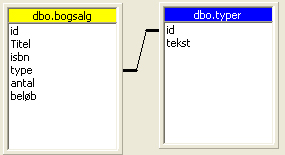
Default har den valgt at linke på id feltet på begge tabeller. I dette tilfælde er det ikke korrekt. Man skal være over den automatiske linker, nogle gange linker den som "de blinde de bokser". Vi skal have flyttet linket fra id på bogsalg til type, da den jo reelt holder nøglen på vores dimensionsværdier. Nu er der tilføjet en enkelt dimension til vores kube, men da man ikke kan lave en kube uden measures skal vi lige tilføje både antal og beløb som measures (højreklik og vælg "insert as measure"). Hvis vi så gemmer og processerer (i den "Design storage" dialog boks der fremkommer klikkes bare "next" hele vejen igennem) vores kube(husk at give den et navn) og bagefter vælger "Data" tabben i bunden vil vi se vores lille primitive kube samt vores Dimension. Der er ikke meget sjov ved den, så prøv at gå tilbage til "Schema" tabben og indsæt "Titel" som en dimension (dette bliver en lokal dimension, men vi bruger den for nuværende til at teste lidt med), Processer data igen og gå til "Data" tabben. Vil vil nu se en oversigt over vores lille analysemiljø. Man kan trække og slippe de forskellige dimensionsværdier på x og y aksen af nedenstående tabel eller vælge andre værdier.
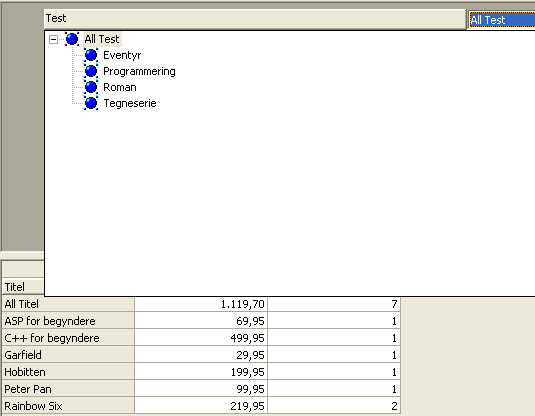
Eller placere det hele på hver sin akse
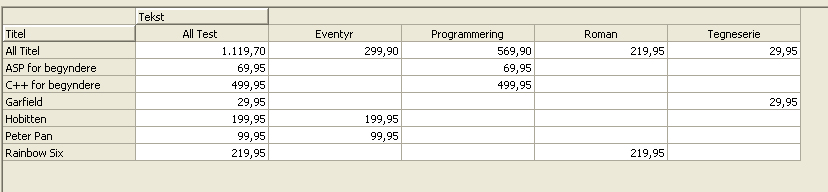
Dette er vores analyse miljø. Denne browser bruges kun til at få et kort overblik over hvordan data ser ud samt kontrollere at tallene stemmer.
Calculated membersEt calculated member er også en measure, denne beregnes blot på runtime tidspunktet og kan laves dynamisk til at afhænge af dimensioner, deres niveauer samt meget andet. I dette eksempel vil vi lave to meget simple calculated members, en der beregner gennemsnit samt en der erstatter en pris med en anden. Det er ikke så værdifuldt rent analysemæssigt, men det giver et meget godt indblik i hvordan MDX virker. For at oprette et calculated member højreklikkes på folderen "Calculated member" og vælges "New calculated member", og herefter kan der oprettes et calculated member.
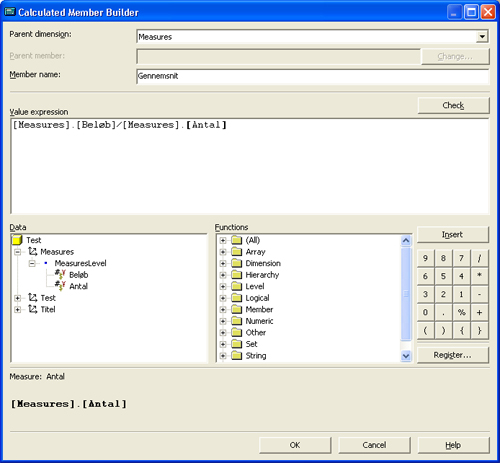
Det smarte ved et calculated member er at det bliver beregnet runtime. Det vil sige at vi ikke behøver at processere kuben for at se de nyeste ændringer.
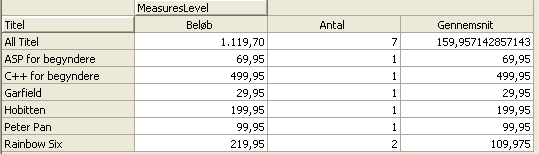
Hvis der laves et nyt calculated member med følgende kode skriver vi om antal for den enkelte række om det er over eller under 1
iif([Measures].[Antal]>1, "over en", "under eller lig med en")
AfslutningAnalysis Services kan tilbyde utrolig mange muligheder med hensyn til at lave analysemiljøer. Denne artikelserie kradser kun lidt i overfladen. Analysis Services tilbyder utrolig mange faciliteter, dog er den ikke beregnet til at analysere direkte i. Her er det udviklerens ansvar at bygge en applikation der kan hente data fra Analysis Services og præsentere dem for brugeren.
Hvad synes du om denne artikel? Giv din mening til kende ved at stemme via pilene til venstre og/eller lægge en kommentar herunder.
Del også gerne artiklen med dine Facebook venner:
Kommentarer (0)
Du skal være
logget ind for at skrive en kommentar.